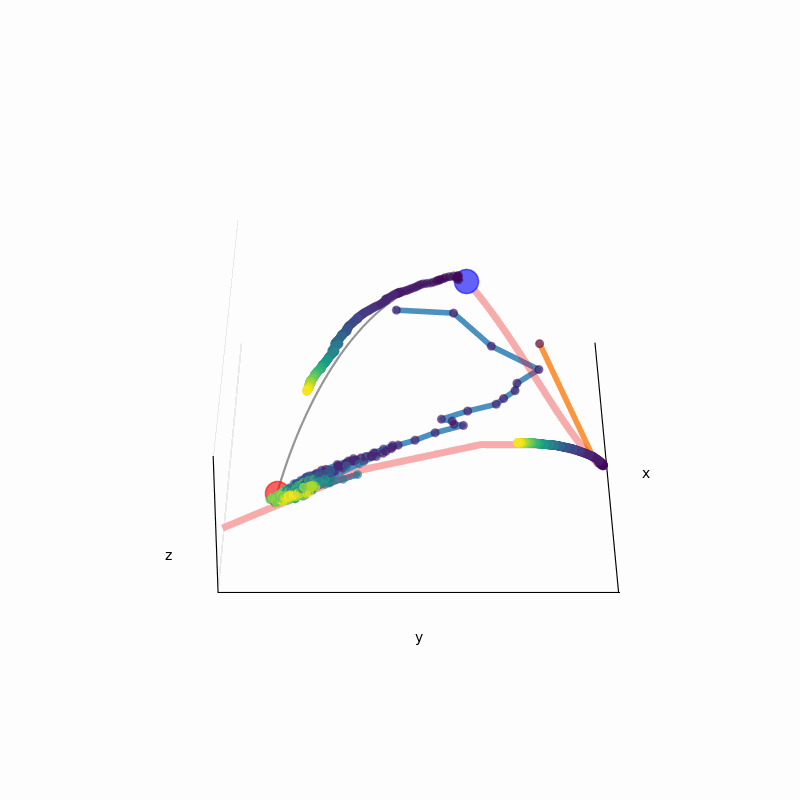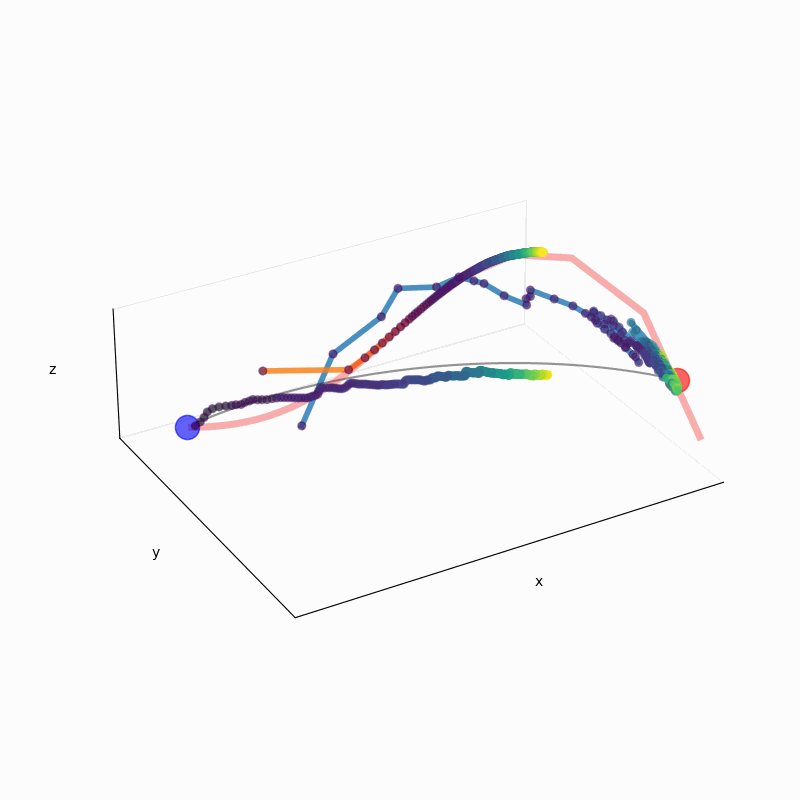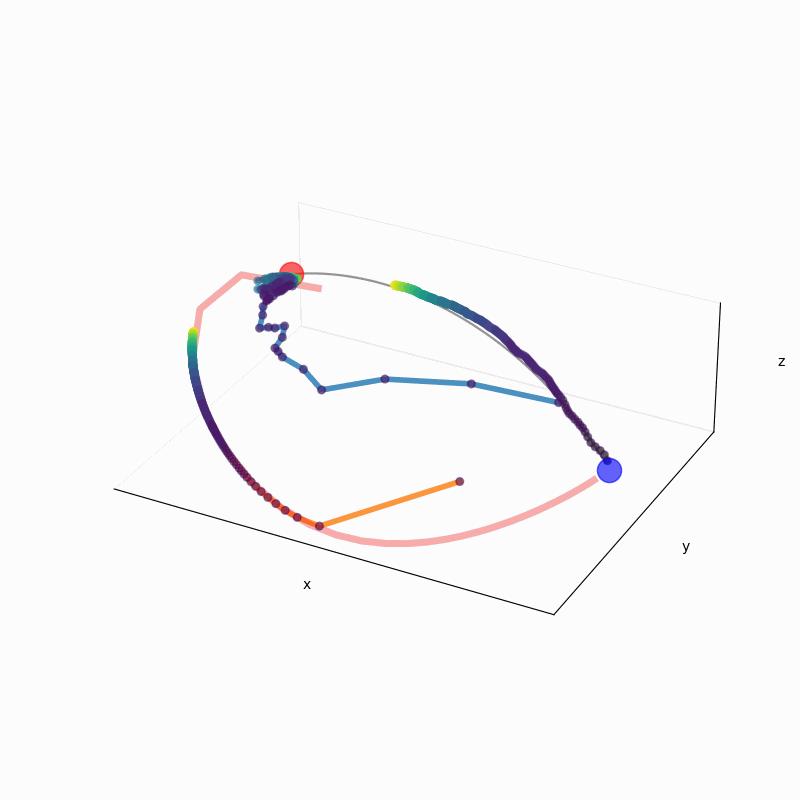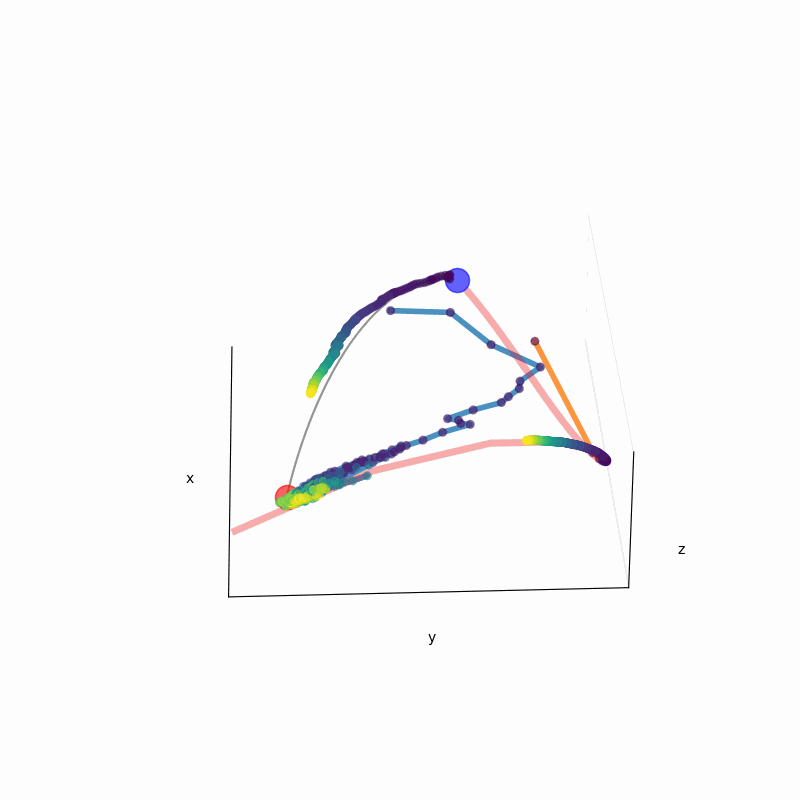Research projects from physics to learning systems
Jacobian Scopes
When an LLM produces an answer, which parts of the input prompt informed that decision?
JacobianScope is a way to compute how much perturbing each input token affects a given target token.
In practice, we project each Jacobian along a probe vector of interest to calculate token-level influence scores.
This is computationally efficient and yields really interesting results for causal attribution.
Semantic Scope reveals the potential for political bias that may be present in models such as LLaMA3.2. The prediction for the subject being a “liberal” is
attributed to the input token “Columbia”, while “conservative” to the token pairs for “the South”.
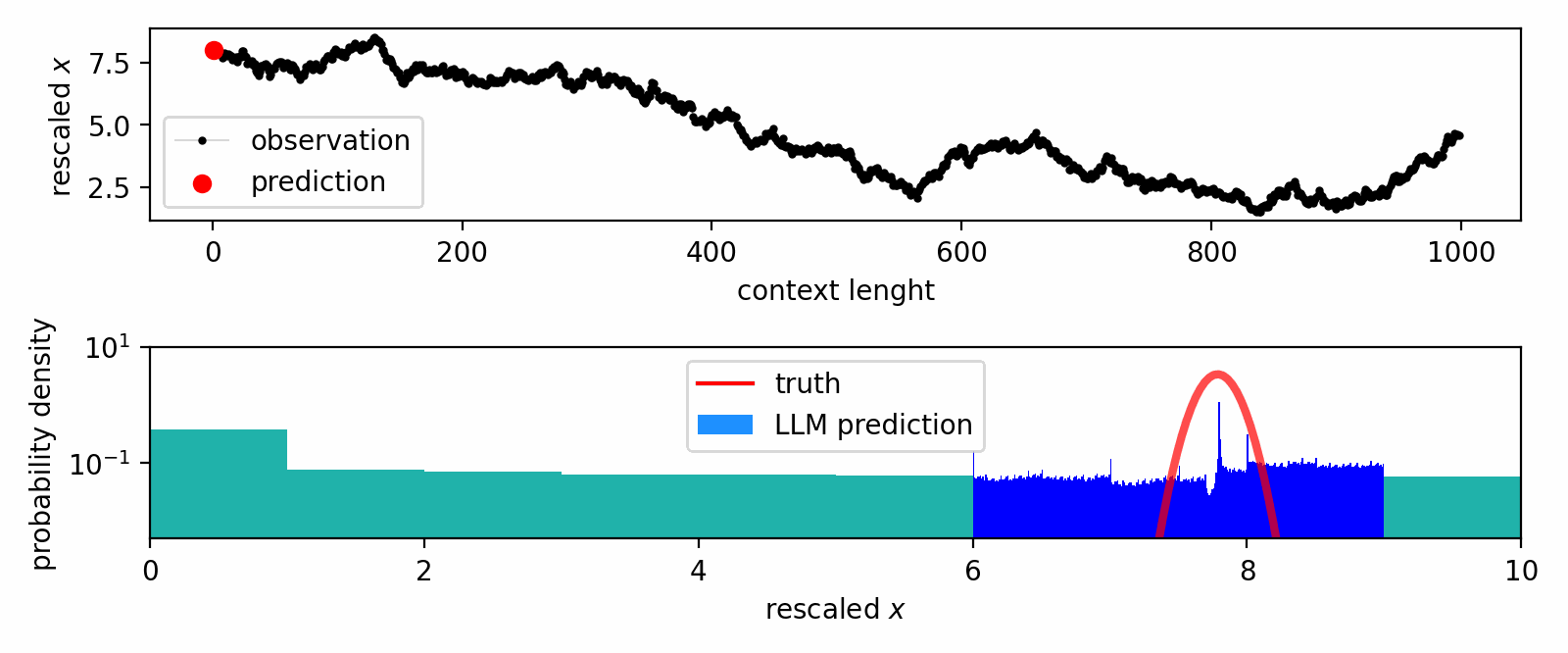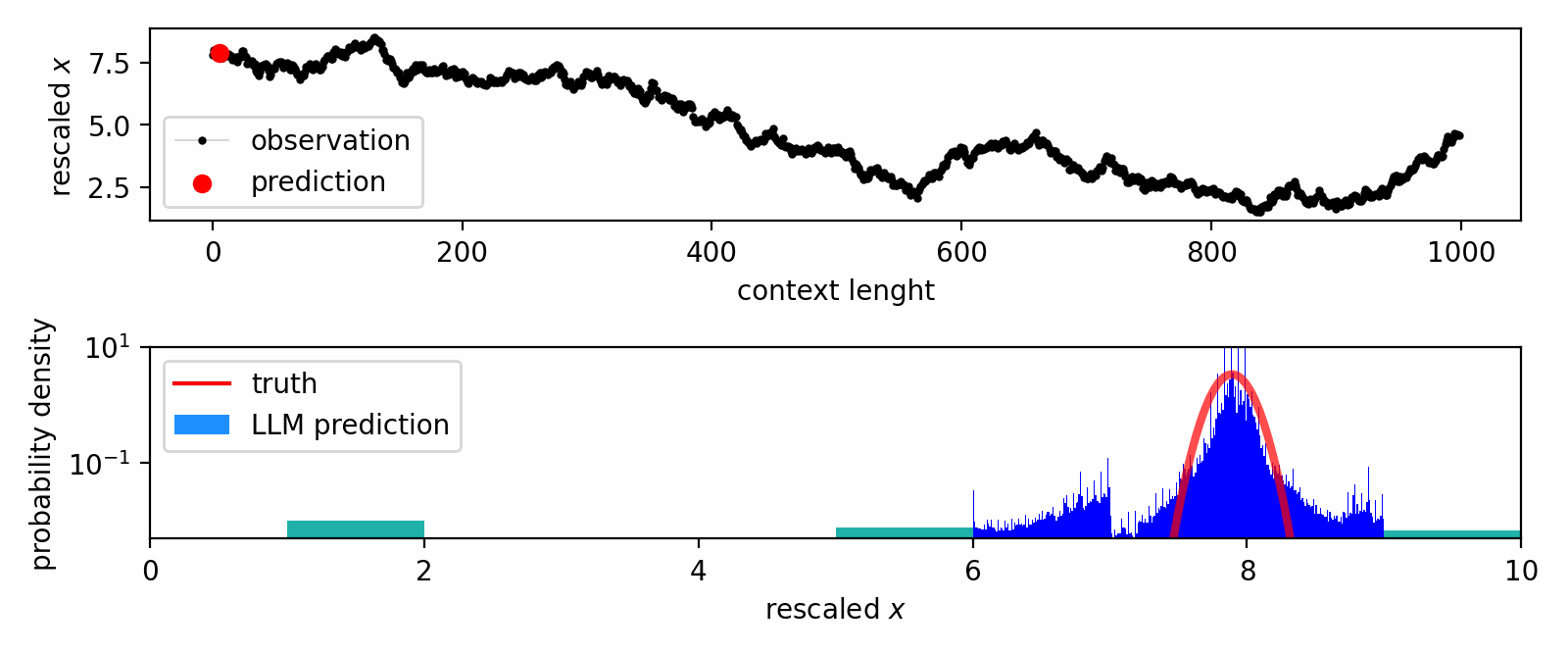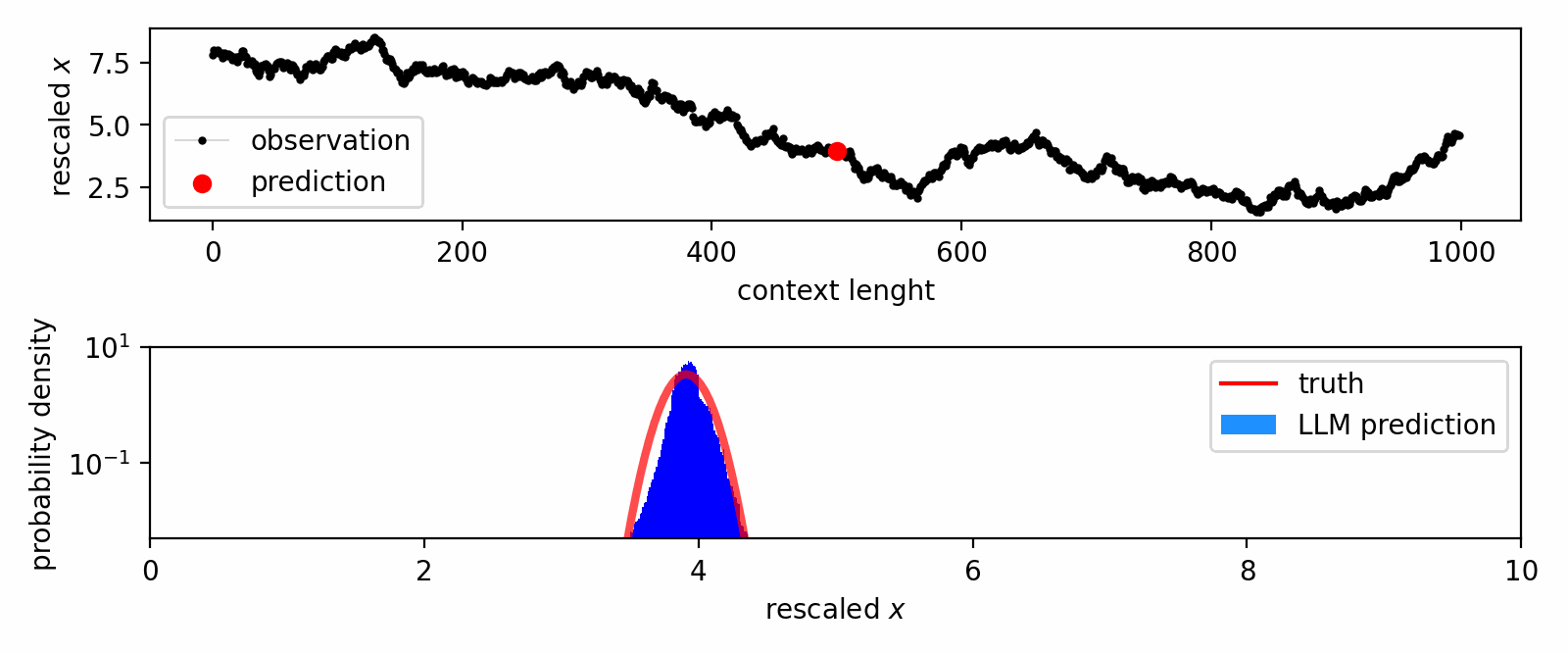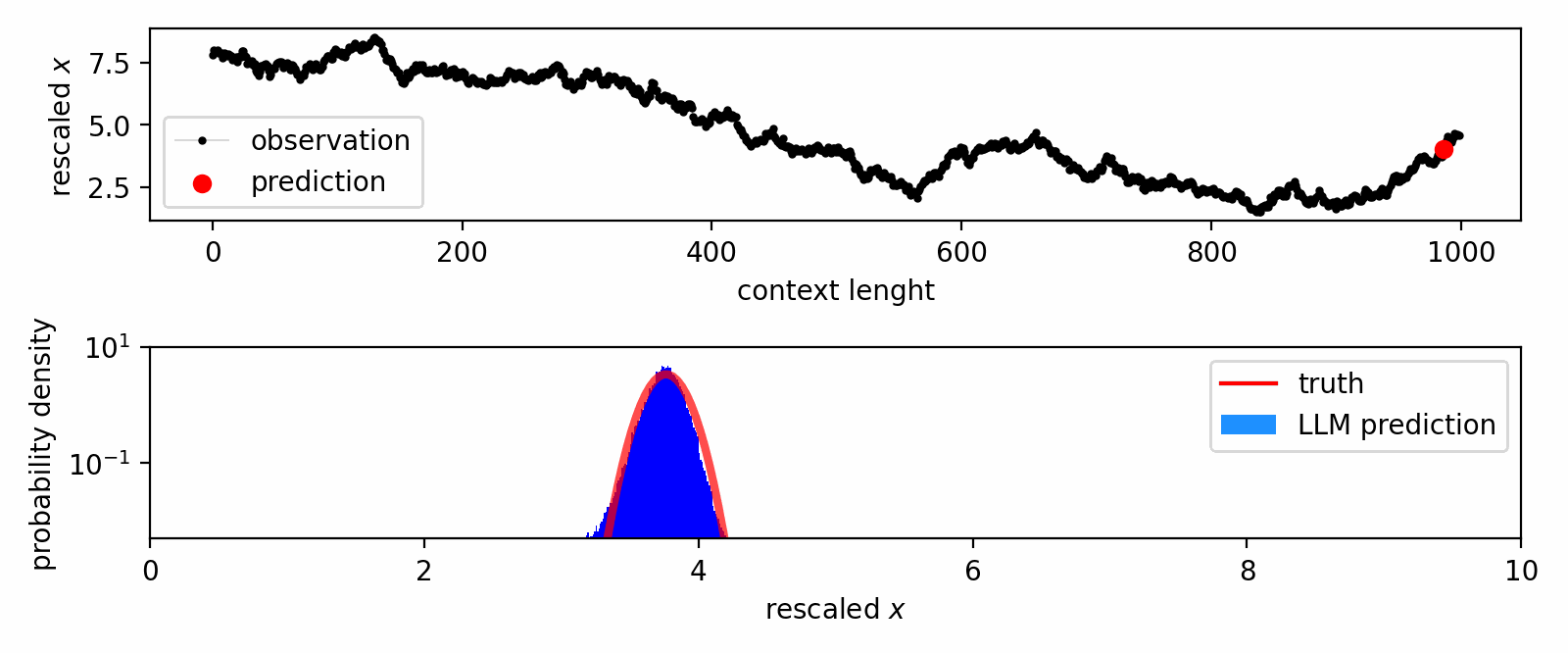
How do large language models learn from in-context data?
We leverage the Intensive Principal Component Analysis to visualize how LLMs estimate the probability density underlying input data.
Our geometric investigation leads to a natural interpretation of LLM's inference process as a kernel density estimator with adaptive kernel width and shape.
In-context DE trajectory of LLaMA 2-70b, compared to Gaussian KDE and Bayesian histogram.
What makes abstract thoughts different from concrete memories?
Considering memories as fixed points within the brain's dynamical system,
we propose to understand abstraction as a hierarchy of slow manifolds,
which serve as coarse-grained roadmaps to these fixed points.
We construct a diffusion RNN (Recurrent Neural Network),
a neural-dynamical model that can perform memorization and abstraction, and
demonstrate its ability to perform dimensionality reduction on the MNIST dataset.
Finally, we present an analytic theory that elucidates the relation between the distribution of data
and the learned slow manifolds.
Diffusion RNN extracts a hierarchy of slow manifolds (red) from dimensionally reduced MNIST data.
Could a pretrained LLM make sense of an unseen, synthetic language, such as, a chain of symbols generated by a random Markov process?
Yes. In fact, we show that LLaMA 2 models possess uncanny abilities to in-context learn
a variety of stochastic systems, physical and symbolic. Our observation reveals an in-context version of neural scaling law.
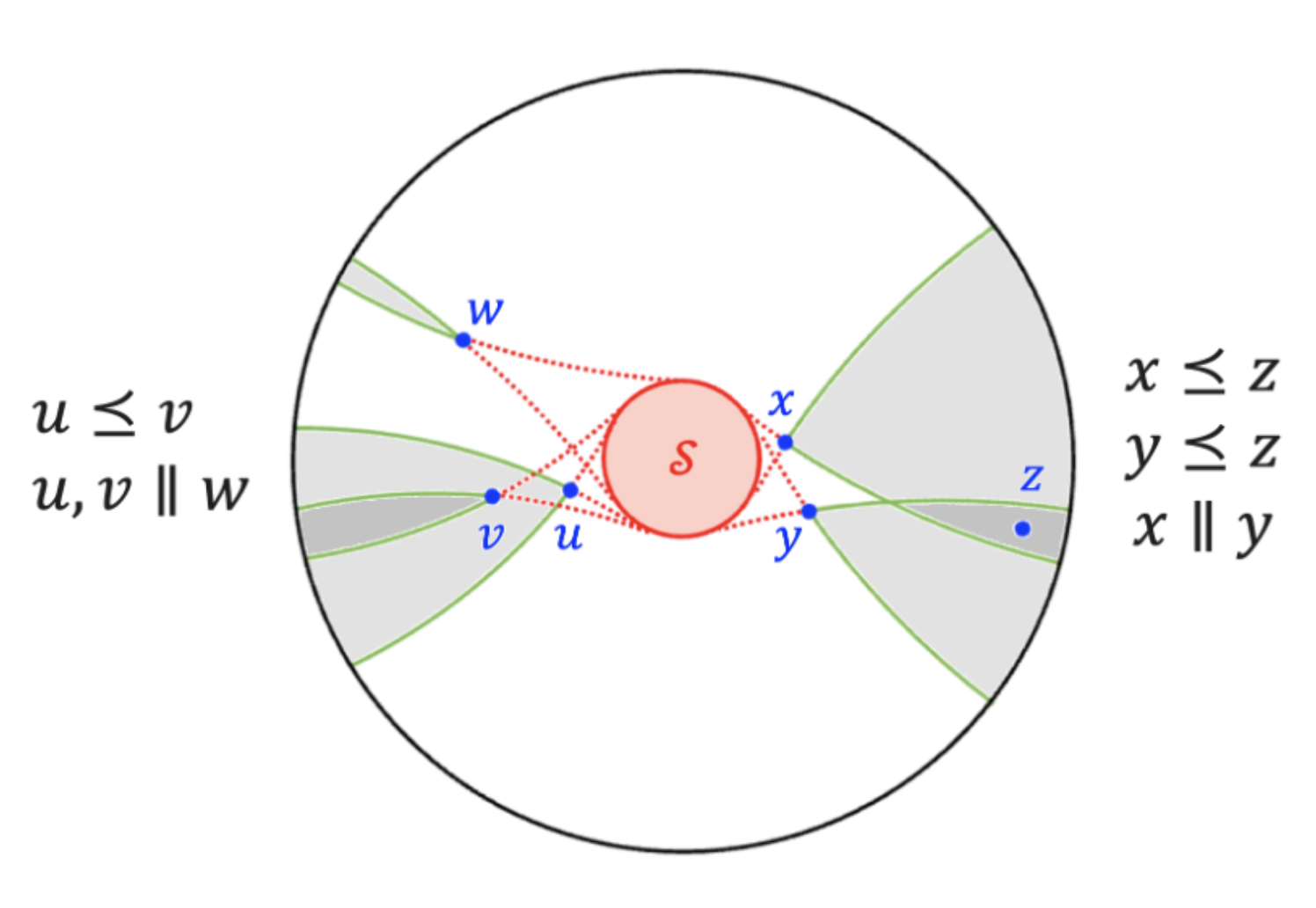
In Euclidean space, the volume of a ball grows polynomially with its radius — but in hyperbolic space,
it grows exponentially. This mirrors a fundamental property of trees: the number of nodes at depth
d grows exponentially with d. This geometric advantage makes hyperbolic space
a natural host for embedding hierarchical data.
We embed hierarchical data by casting shadows: a light source projects opaque objects onto a plane, where
parent-child relationships correspond to shadow containment — a child node is represented by an object
whose shadow falls entirely within its parent's.
This geometric picture yields a fast embedding algorithm: to embed a tree, one simply places
objects such that the containment constraints are satisfied, with deeper nodes casting smaller,
nested shadows.
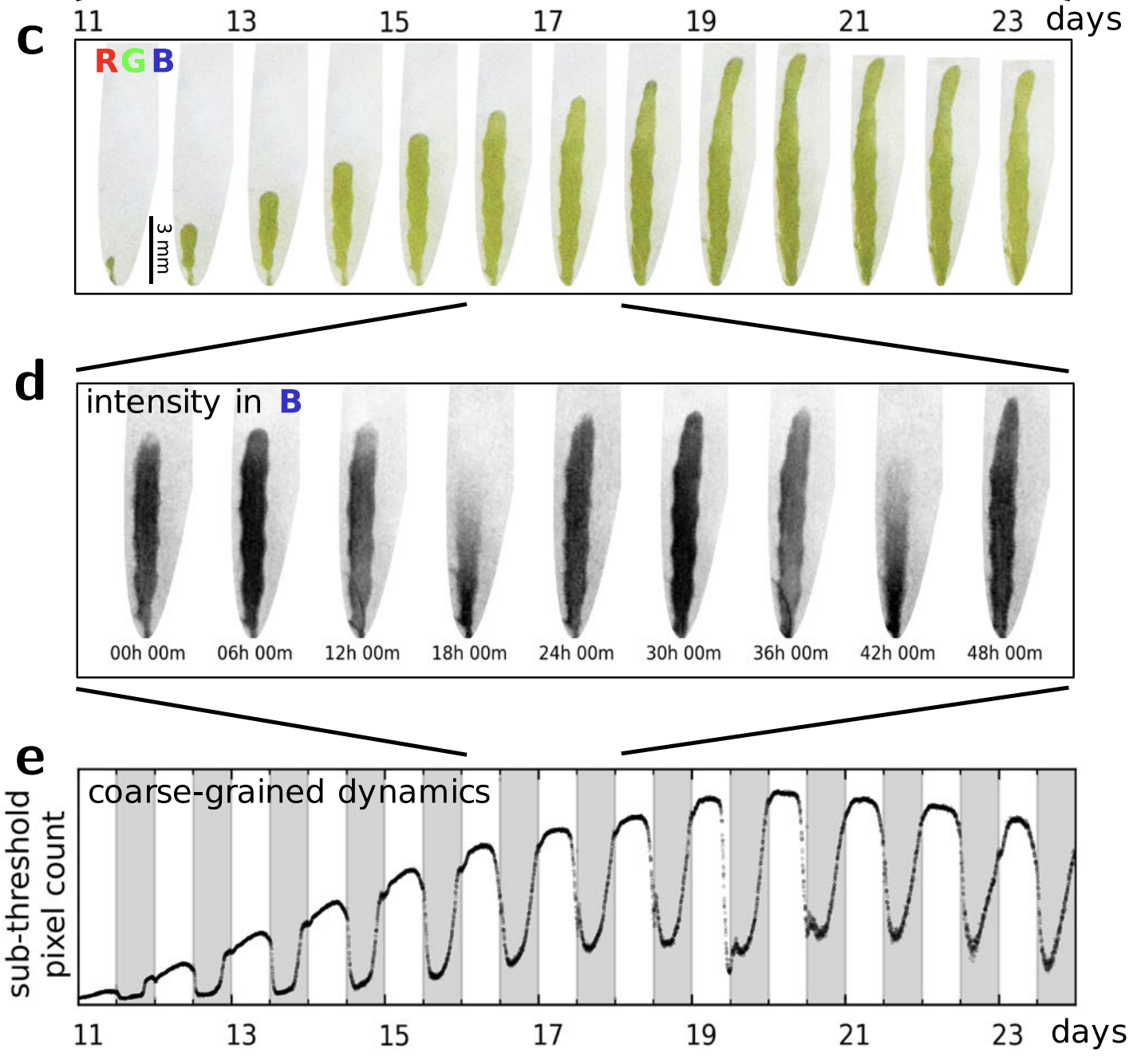
How do plants anticipate external environemnts and regulate internal states?
We perturb marine algae with patterned illumination, and analyze the response dynamics using
image analysis and reduced-dimension observables.
Our experiment and analysis unveils wave-like patterns entrained by external illuminations, and coupled to a circadian internal oscillator.